

- HOME
- Information for Authors
- Call for Papers
- Scientific Areas
- Important Dates
- Paper Submission
- Registration
- Instructions for Presenters
- Visitor Information
- Program
- Conference Program
- Author Index
- Keynote Speakers
- Tutorial
- Special Sessions
- Venue
- Accommodation
- Social/Tour Programmes
- Satellite Meetings
- Paper Awards

- Photo Gallery
- Video Show
- Proceedings
- Abstract Book
- Organization
- Committees
- SProSIG
- Contact Us
- Sponsors
- Supporting Institutions
- Exhibitors
- News

The Speech Prosody 2012 Organizing Committee is pleased to announce the distinguished Tutorial at the conference:
Time: 21 May 2012 (Monday) 14:00 - 17:00
Place: Tongji University (School of Foreign Languages), 1239 Siping Road
Important Notes:
1. This tutorial is free of charge for all registered participants of Speech Prosody 2012.
2. If you plan to attend the tutorial, could you please send us (sp2012@tongji.edu.cn) a message, so that we would be able to get a general idea of the number of audience for the preparation, thank you very much for your cooperation!
Moreover, you are kindly required to bring your laptop with you.
Please download the materials for the tutorial from http://www.homepages.ucl.ac.uk/~ucjtsp2/PENTATrainer_CD.zip
And make sure that the following list of required software is installed at your laptop for the tutorial:
1) PENTATrainer 2.0
You can find it in the folder "program" in the downloadable material file.
http://www.homepages.ucl.ac.uk/~ucjtsp2/PENTATrainer_CD.zip
You can also find it on your USB stick in your SP registration bag.
If you have not downloaded the file or have not got the USB stick, you can copy it from the CDs on the tutorial day.
2) Praat version 5.3 or newer (http://www.fon.hum.uva.nl/praat/)
3) Java Runtime Environment version 1.6 or newer (http://www.java.com)
4) (optional) Audio Editing Software (e.g. Audacity (http://audacity.sourceforge.net/)
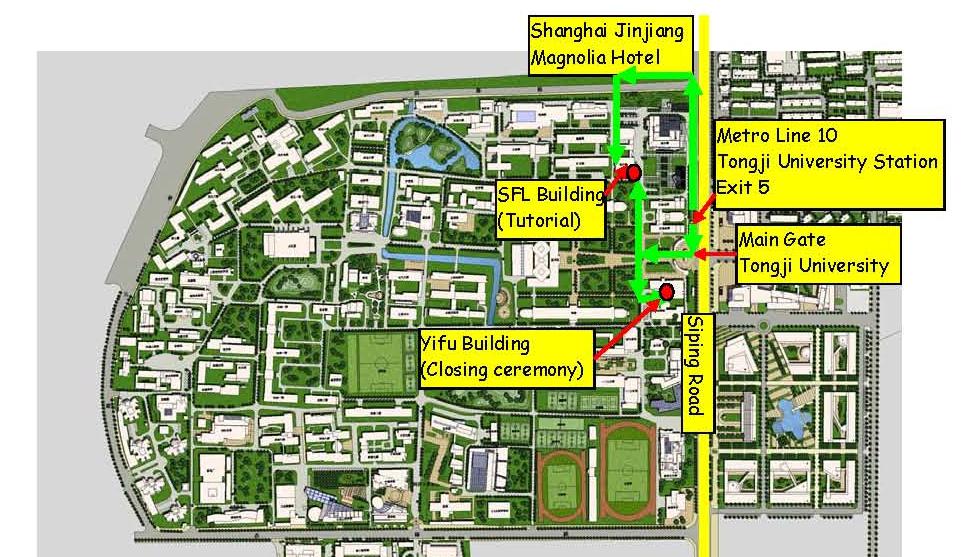
3. Guide to School of Foreign Languages (SFL) Tongji University:
Take Metro Line 10 (direction: New Jiangwan City) from East Nanjing Rd. (Grand Central Hotel), and get off at Tongji University Station. Get out of the station from Exit 5 and turn right. You will find the main gate of Tongji University, after entering the main gate go forward and then turn to the right, SFL building is on the left side of the road (please use the map below).
Analysis and synthesis of speech prosody based on articulatory dynamics and communicative functions: from concept to practice
Duration:
3 hours
Presenters:
Dr. Yi Xu, Reader in Speech Science
Dr. Santitham Prom-on, Newton Fellow
 Dr. Yi Xu, Reader in Speech Science
Dr. Yi Xu, Reader in Speech Science
Department of Speech, Hearing and Phonetic Sciences,
Division of Psychology and Language Sciences, University College London, UK
Homepage: http://www.phon.ucl.ac.uk/home/yi/
E-mail: yi.xu@ucl.ac.uk
Dr. Xu received his Ph.D. in Linguistics from the University of Connecticut in 1993, and then worked as a postdoctoral fellow at Massachusetts Institute of Technology. He later served as a faculty member at Northwestern University and as a researcher at the University of Chicago and Haskins Laboratories. He was hired as a lecturer at University College London in 2004 and became a Reader there in 2006. Dr. Xu has published widely since 1986, covering topics on the production, perception and theoretical modeling of tone, intonation, segment and the syllable. He has also done work on auditory feedback in speech production, emotion in speech, short-term memory in reading and neural-network simulation of acquisition of tone and intonation. His early work was focused mainly on how lexical tones in Mandarin were produced and perceived in continuous speech. From this work he developed the Target Approximation model (TA). He then extended the model to intonation in the form of the Parallel Encoding and Target Approximation model (PENTA). His most recent work has attempted to extend TA to speech production in general. He has served on the editorial board of Phonetica since 2004.
Selected Publications
- Xu, Y. (2011). Speech prosody: A methodological review. Journal of Speech Sciences 1: 85-115.
- Prom-on, S., Xu, Y. and Thipakorn, B. (2009) “Modeling tone and intonation in Mandarin and English as a process of target approximation” Journal of the Acoustical Society of America 125: 405-424.
- Xu, Y. (2009). Timing and coordination in tone and intonation--An articulatory-functional perspective. Lingua 119(6): 906-927.
- Xu, Y. (2005) “Speech melody as articulatorily implemented communicative functions” Speech Communication 46, 220-251.
- Xu, Y. and Wang, Q. E. (2001) “Pitch targets and their realization: Evidence from Mandarin Chinese” Speech Communication 33, 319-337.
 Dr. Santitham Prom-on, Newton Fellow
Dr. Santitham Prom-on, Newton Fellow
Department of Speech, Hearing and Phonetic Sciences,
Division of Psychology and Language Sciences, University College London, UK
Homepage: http://www.ucl.ac.uk/psychlangsci/staff/research-associates/s_prom-on
E-mail: santitham.prom-on@ucl.ac.uk
Dr. Prom-on received his PhD in Electrical and Computer Engineering from the King Mongkut's University of Technology Thonburi, Bangkok, Thailand in 2009. In 2011, he was awarded a Newton International Fellowship, which is the most prestigious post-doctoral research program in the UK and established by the Royal Society, the Royal Academy of Engineering, and the British Academy. He is currently working as a Newton Fellow at the University College London. Dr. Prom-on's research focuses on computational modeling of speech prosody based on communicative functions and articulatory dynamics. His latest work is the development of a generalized prosody analysis and synthesis platform.
Selected Publications
- Prom-on, S., Xu, Y. and Thipakorn, B. (2009) “Modeling tone and intonation in Mandarin and English as a process of target approximation” Journal of the Acoustical Society of America 125: 405-424.
- Prom-on, S., Liu, F. and Xu, Y. (2011) “Functional Modeling of Tone, Focus and Sentence Type in Mandarin Chinese” Proceedings of ICPhS 2011, pp. 1638-1641
- Prom-on, S., Xu., Y. and Liu, F. (2011) “Simulating Post-L F0 Bouncing by Modeling Articulatory Dynamics” Proceedings of INTERSPEECH 2011, pp. 289-292.
- Prom-on S., (2008). “Pitch target analysis of Thai tones using quantitative target approximation model and unsupervised clustering” Proceedings of INTERSPEECH 2008, pp. 1116-1119.
Material:
- Tutorial handout (paper)
- Tutorial CD, which contains
- PENTATrainer program
- PENTATrainer user manual
- Tutorial handout (pdf)
- Demonstration files
Equipment
- LCD projector
- Loud speaker
- Internet connection
Introduction:
The significance of prosody research is not only the contribution to basic knowledge in speech science but also the advancement in speech technology, particularly speech synthesis. In the last decade, we have seen rapid developments in prosody research. Further advances in this area depend much on the effectiveness of the acoustic analysis as well as quantitative modeling strategies employed in the investigations.
Prosody research so far has mainly relied on a reductionism paradigm, i.e. the data in acoustic forms are summarized into prosodic events. Descriptive models of the prosodic events are often formed afterwards. This process is, however, incomplete, because the observations may lead to a variety of models. An improved practice should be to further test the proposed models by regenerating the complete acoustic features based on the model and comparing them to the originals. This should offer us truly rigorous tests of predictive power of theories and models of speech prosody.
This tutorial aims to provide a comprehensive procedure for systematically studying prosody based on a user-friendly prosody modeling program (a.k.a PENTATrainer) that can be used for both analysis and synthesis purposes. PENTATrainer analyzes F0 contours based on user-specified functional annotation on the one hand and the program-internal Target Approximation model. The program uses analysis-by-synthesis to determine the optimal parameters for user-defined prosodic categories. By using a stochastic optimization method, the program automatically optimizes the model parameters that can be readily used in synthesis. The same parameters, meanwhile, can also be used as measurements for analysis purposes. Because the users can flexibly define the prosodic categories (in the form of annotation), the system is at least partially theory-neutral, and it is applicable to any languages.
The main target audience for this tutorial is the speech researchers who wish to investigate, model, or synthesize speech prosody. The program can be applied in either small-scale pilot studies or large-scale multi-corpus investigations.
Presentation Outline: (maximum 2 pages)
The tutorial consists of three 40-minute lectures and a 60-minutes interactive hands-on session.
- Introduction (duration: 30 minutes, presenter: Yi Xu)
- Communicative functions in speech prosody
- Parallel encoding and target approximation
- Modeling speech prosody
- Analysis-by-synthesis approach
- Designing the experiment for investigating communicative functions (duration: 30 minutes, presenter: Yi Xu)
- Corpus design
- Result interpretation
- Known issues
- PENTATrainer for prosodic analysis and synthesis (duration: 40 minutes, presenter: Santitham Prom-on)
- Core module
- Error measurement
- Learning algorithm
- Program workflow
- Interactive hands-on session with Q&A (duration: 80 minutes, presenter: Santitham Prom-on, Yi Xu)
- Prosody analysis case study
- Prosody synthesis case study